在我们日常的工作中,尤其是工作很忙的时候,如果项目组要求每天都要写日报,这真的是一件令人很难受的事情。因为我们老是忘记这件事情。而且,每天打开日志,输入帐号密码,然后敲一堆文字,保存日志…,像这样的重复劳动也很是让人恼火。既然我们是程序员,那么肯定会有办法来解决这个问题。于是乎,哈哈,是时候祭出今天我们要使用的神器了:puppeteer。
puppeteer是谷歌做的一个无头浏览器,并且暴露出相应的api使得用户可以用js教本来对浏览器进行操作。puppeteer的本来用途应该是用来做web前端自动化测试的,但是由于其功能的强大,不少人也开始用其来做爬虫或者一些其它的事情。
由于我们使用的大部分日报提交系统都是基于web的,所以就给我们使用puppeteer带来了先决条件。
1.准备工作
和普通的node安装包安装方法一致,我们这里使用的是0.12版本,截止到本文完成前,官方已经是出到了0.13,但是api方面有些许改动,这里我们就用前一个比较稳定的版本即可。
直接在项目根目录使用
1 | npm install puppeteer@0.12.0 --save |
不过这里有一点值的注意,puppeteer基本上是一个基于异步的框架,我们需要大量的使用asyn/await,所以,我们需要使用更高版本的node,这里我们只要node版本在v7.6.0以上就可以了。
另外,我们还需要自己准备好chromium浏览器,这个我们需要翻翻墙从外网下载,版本的话当然是越新越好,v59以上就可用。这里还有一点值的注意,官方的npm包中会自动给我们去下载一个chromium浏览器,但是由于国内的网络环境问题,我们是下载不了的,而且整个的安装过程会因为无法安装这个玩意而死掉,这里我们需要在当前开发环境中设置下:
1 | set PUPPETEER_SKIP_CHROMIUM_DOWNLOAD=1 |
这样就能跳过puppeteer自带的chromium安装。
2.开始使用
当我们的chromium和puppeteer安装完成后,我们就可以开始把我们的无头浏览器跑起来了。
代码如下:
1 |
|
这段代码来自puppeteer的官方文档.这里我们把原来的example.com换成了国内的baidu.com,最后运行的结果会在当前目录下生成一张百度的首页截图。
但是如果我们是自己手动安装的chromium浏览器,很可能会因为找不到启动路径,而无法正常运行,这里我们改下:
1 |
|
我们可以自己去配置我们的chromium的安装位置,然后通过关闭掉浏览器的无头模式,这样可以看到我们操作浏览器的整个流程。
3.分析目标网页
好了,虽然我们对puppeteer还不是很熟悉,但是我们可以一边读着开发文档,一边来完成我们的自动化日报脚本了。
这里我们使用日事情作为我们的目标网站,如果你是用的其它的项目日报管理软件,也是没问题的,只要弄明白puppeteer的工作原理。
分析网页的工作主要是通过浏览器控制台来获取我们所需要元素的标签名,或者id,class名,如下图在火狐中调试日事清的登录页面:
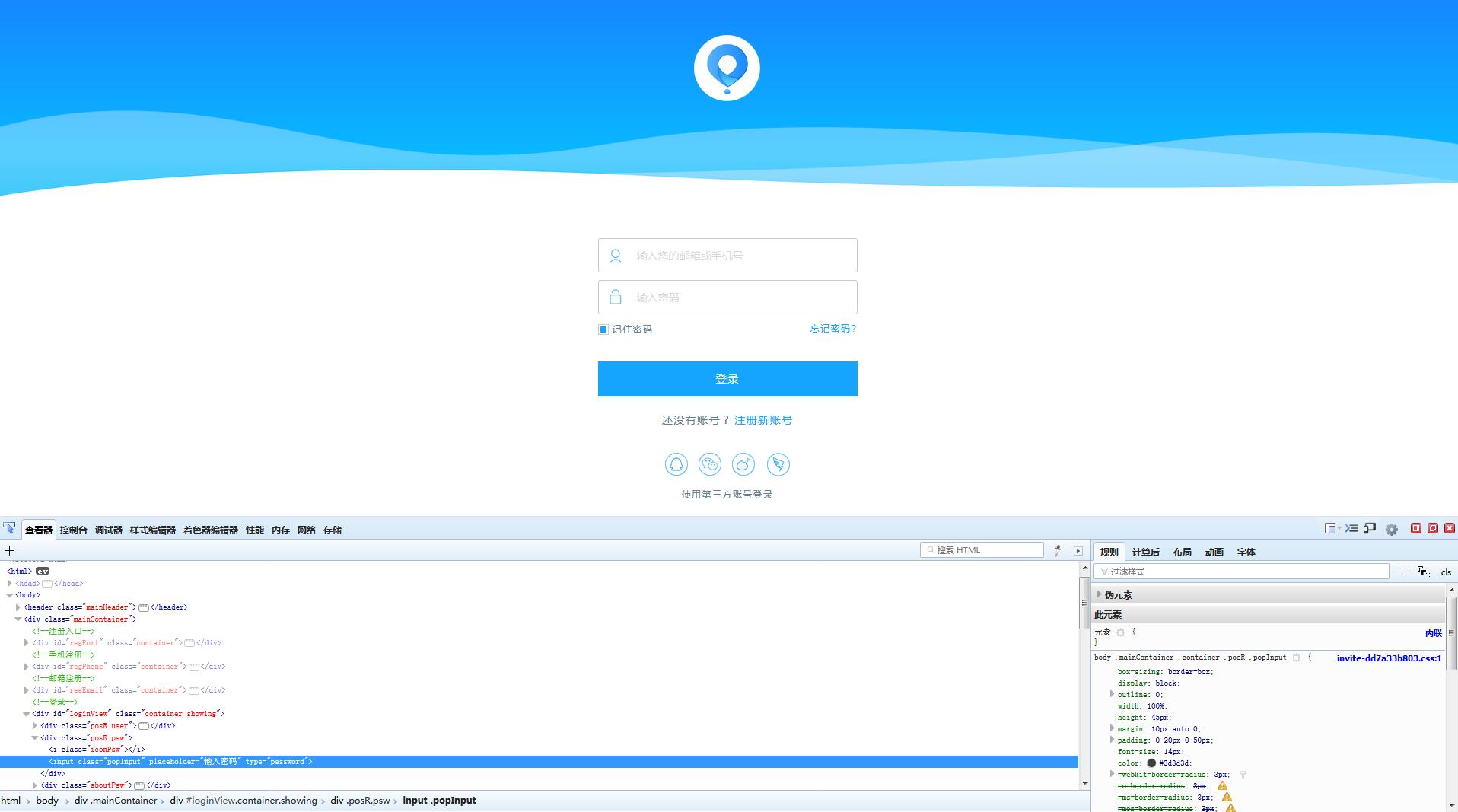
当我们拿到了其各个输入框和按钮的名称之后,我们就可以开始使用puppeteer来模拟用户操作了:
1 |
|
1 | await page.goto(INDEX_URL); |
允许玩家打开一个新页面,
1 | await page.waitForNavigation({ waitUntil: "networkidle"}); |
将会等待浏览器将页面加载完,这里传了一个相应的参数进去,直到网络的状态为”networkidle”的时候才会去执行下一步。
puppeteer允许我们像使用jquery一样的去使用选择器,就像这样的方法:
1 | let account = await page.$('[placeholder=输入您的邮箱或手机号]'); |
查找一个指定了placeholder的输入框。之后我们还使用了更为稳定的方法:
1 | await page.waitForSelector(".new-doc-item"); |
如果这个选择器没有被加载出来,那么整个puppeteer的进程会一直停在这里,不会去执行接下来的代码。这也防止了拿空按钮做点击的情况发生。
后续的过程也是很简单,这是模拟了一次用户的点击事件:
1 | await page.click('div.mainContainer div#loginView.container.showing div.btn'); |
接下来是模拟用户的输入事件,delay为每次输入之后的间隔时间。
1 | await page.type('.editArea',dailyText,{delay:120}); |
最后提交日报,然后关闭掉浏览器。整个流程可以说和我们平时的人工操作是完全一模一样的。
这里还要解释下我们引入的两个js文件,一个是config.js,一个是tool.js。config.js是用户的账号和密码配置,这里我就不列出来了,tool.js是一个简单的工具文件,我们在上面所有用到的timeout方法,都是来自此处的定义。timeout方法的写法也很简单,就是返回一个指定时间返回的promise。
1 |
|
因为await的作用就是使进程等待这个promise的返回,只有当promise resolve的时候,才会开始执行之后的代码。所以这里就起了简单的暂停作用。有时候,我们希望在这个页面先停留一段时间,然后做些别的操作,这样,我们使用定义好的timeout函数就可以了。
3.配置winodws的计划任务
当我们完成了基本的脚本功能后,我们就得开始把这个脚本配置到windows的计划任务当中去,让他每天早上,自动的帮我们生成今天的日报。
具体的做法是首先在当前目录下创建一个autorun.bat的脚本,然后用编辑器打开:
1 | cd %~d0\yourpath\AutoRishiqing && node %~d0\yourpath\AutoRishiqing/src/index.js |
接下来我们将自己的bat脚本配置到windows的计划任务中去:
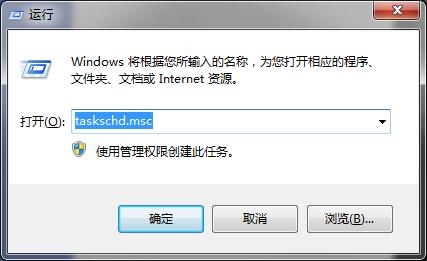
我们按win+r打开运行,然后输入taskschd.msc进入任务计划程序,点击右侧创建任务,设置好任务名称,在触发器中设置好启动时间,选择好我们之前写的bat脚本就可以了。
4.小结
puppeteer的基本使用还是很简单的,官方也有比较详尽的api文档(目前还没有中文版),这里主要的问题可能是来自await和promise的使用,作为ES6(ES7)中的重要特性,我觉得还是每个js必须要掌握的,值得去花时间学习。